Best practices datamodel
/ 6 minuten leestijd

Je datamodel is een van de belangrijkste onderdelen van Power BI. Hierin leg je alle relaties tussen de tabellen vast. Dit is uiteindelijk de fundering van je Power BI rapport. Wanneer je zorgt voor een sterk datamodel verklein je de kans op “vertraging” wanneer je gaat bouwen.
Je koppelt de tabellen die je wilt gebruiken in Power BI. As always, laat je nog een aantal transformaties los op je data en klik je daarna op ‘close & apply’. Afhankelijk van je instellingen zoekt Power BI zelf mogelijke relaties tussen je tabellen. Of je doet dit zelf, hierover later meer.
Onze BI consultant Puck deelt 5 best practices met je voor het maken van een datamodel in Power BI! Heb je vragen of ben je bezig met een Power BI project? Laat het ons weten!
1. Een Patrick of Elsa datamodel? 🌟
Alle gekheid op een stokje, we gaan geen sprookjes schrijven, maar een krachtig datamodel bouwen. Een datamodel kan twee verschillende vormen hebben: een Star model of een Snowflake model. We nemen ze even met je door. Een Star model is makkelijker om te lezen en verkleint de kans op redundantie. Ook zorgt het voor eenvoudigere queries en kan het de performance van je rapport verbeteren. Een Snowflake model is wat complexer om te lezen en wordt vaak gebruikt bij grote, complexe databases. In sommige gevallen zijn Snowflake modellen makkelijker te onderhouden. Hieronder een voorbeeld van zowel een Star als een Snowflake model.
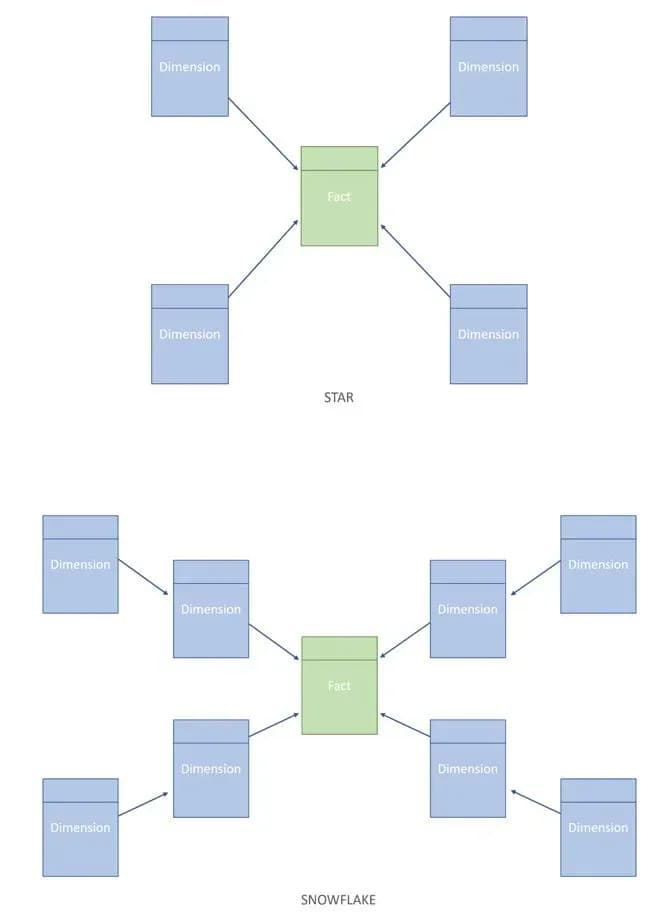
De best practice is om voor een Star model te gaan. Houdt wel in de gaten dat jouw data misschien niet gelijk klaar is voor het gebruik van een Star model. Dit kan komen doordat er bijvoorbeeld 2 dimensie tabellen elkaar aanvullen. Bijvoorbeeld: je hebt een werknemer tabel en leidinggevende tabel (2 dimensie tabellen). Om daar dan toch een Star model van te kunnen maken, kan je de twee dimensie tabellen samenvoegen (merging). Hiermee zorg je ervoor dat er in de werknemer tabel een kolom bij komt met de naam en functie van de leidinggevende. De aparte leidinggevende tabel is niet meer nodig en kun je uit jouw datamodel halen. Kortom: Patrick boven Elsa in het geval van data modelling 😉 (meestal dan).
2. Relaties leggen in je data model
Bij het leggen van relaties zijn twee best practices belangrijk om in je achterhoofd te houden: gebruik zo min mogelijk many-to-many (M:N) en bi-directional relaties. Stel, je legt een many-to-many relatie tussen een dimensie en een fact tabel. En je hebt bijvoorbeeld een tabel met facturen waarbij meerdere facturen hetzelfde factuurnummer hebben. Hoe vind je dan de juiste factuur voor een klant op basis van factuurnummer? Juist. Dat wordt lastig. Best practice is dan dus ook om zoveel mogelijk gebruik te maken van one-to-many relaties (1:M).
Ook wordt het gebruik van bi-directional relaties afgeraden in je data model. Deze relatie houdt in dat de filter functie beide kanten op werkt. Wanneer je de fact tabel filtert, gebeurt dit ook voor je dimensie tabel. Dit kan ervoor zorgen dat bepaalde data in visuals niet goed wordt weergegeven.
Beide gevallen zorgen ervoor dat Power BI meerdere paden moet controleren met meerdere datapunten. Dit is niet top voor je rapport performance. Het kan voorkomen dat Power BI automatisch relaties legt, afhankelijk van je instellingen. Puck adviseert om deze instelling uit te zetten. Zo heb je zelf controle over de relaties die worden gelegd in je datamodel.
3. Data types – wat is jouw type?
Je gaat je data bewerken zodra alle data is ingeladen in de Query Editor van Power BI. Vaak pas je de data types aan. Power BI slaat de data heel anders op dan bijvoorbeeld Excel. Waarbij Excel alle regels exact opslaat, rekent Power BI uit hoe vaak iets voorkomt. Dat is het enige dat Power BI onthoudt. Het is daarom belangrijk om data zo min mogelijk uniek te houden. Stel dat er een regel ID in de fact tabel wordt meegegeven uit de database voor iedere unieke ID. Dit zou ervoor zorgen dat Power BI alsnog alle regels apart moet opslaan. Hierdoor wordt het rapport onnodig groot, want die kolom ga je waarschijnlijk niet gebruiken. Om diezelfde reden zijn kolommen met tekst lastiger te verwerken dan kolommen met getallen. Hier kan je dus rekening mee houden tijdens het toewijzen van de data types.
Een andere tip van Puck: kijk ook naar je date/time kolommen. Wanneer je een kolom hebt waar naast de datum ook een tijd wordt weergegeven, is het handig om deze kolommen te splitsen. Zo hoeft Power Bi (voor 1 jaar) maar 365 data en 1.440 minuten te onthouden. Een eenvoudige stap met een positief effect op de grootte en performance van je rapport.
4. Datum tabel – dit is er gaande achter de schermen
Vaak maken we gebruik van een datum in onze Power BI rapporten. Power BI maakt voor elke kolom waar een datum in staat een datumtabel aan op de achtergrond. Ofwel, wanneer je in meerdere tabellen een datumveld hebt staan, worden er op de achtergrond meerdere datumtabellen aangemaakt. Zoals verwacht, dit is niet top voor de performance van je Power BI rapport. Best practice is dan ook om een aparte datum tabel aan te maken en deze als zodanig aan te merken. En je wilt hier natuurlijk zelf ook de controle over. De instelling die ervoor zorgt dat er op de achtergrond automatisch datum en tijd tabellen worden gemaakt, kun je uitschakelen.
5. Ruim je datamodel lekker op
Wanneer je je data gaat inladen in het datamodel, probeer je er voor te zorgen dat je zo min mogelijk “overbodige” data mee laat gaan. Het ideale plaatje is natuurlijk dat de brondata ervoor zorgt dat dit niet gebeurd. Mocht dit nou niet kunnen, no worries, daar hebben we o.a. de Query Editor voor.
Wanneer je je data gaat inladen in het datamodel, probeer je er voor te zorgen dat je zo min mogelijk “overbodige” data mee laat gaan. Het ideale plaatje is natuurlijk dat de brondata ervoor zorgt dat dit niet gebeurd. Mocht dit nou niet kunnen, no worries, daar hebben we o.a. de Query Editor voor.
Check dan ook gelijk of alle measures wel worden gebruikt in je rapport. Tijdens het maken van je Power BI rapport maak je vaak veel measures waarvan je misschien achteraf denkt “toch niet handig.” Onze tip: verwijder ze meteen, zodat je verwarring kunt voorkomen. Als je dan toch bezig bent, kijk dan ook even of je ongebruikte tabellen hebt in je rapport. Voordat je op de deleteknop drukt, controleer of het een hulptabel is voor een andere tabel. De hulptabel kun je uit je datamodel halen, mits je in de Query Editor eventjes ‘enable load’ uitvinkt . Zo kun je nog steeds binnen de Query Editor in andere tabellen naar deze tabel verwijzen. Alleen wordt de hulptabel niet meegenomen in het laden van je datamodel.
Wil jij een keer sparren? Of kletsen over wat wij voor jou kunnen betekenen? Neem dan zeker contact met ons op 😄!